Siehe Chapter 6 aus: Head-First-Android-Development-2015
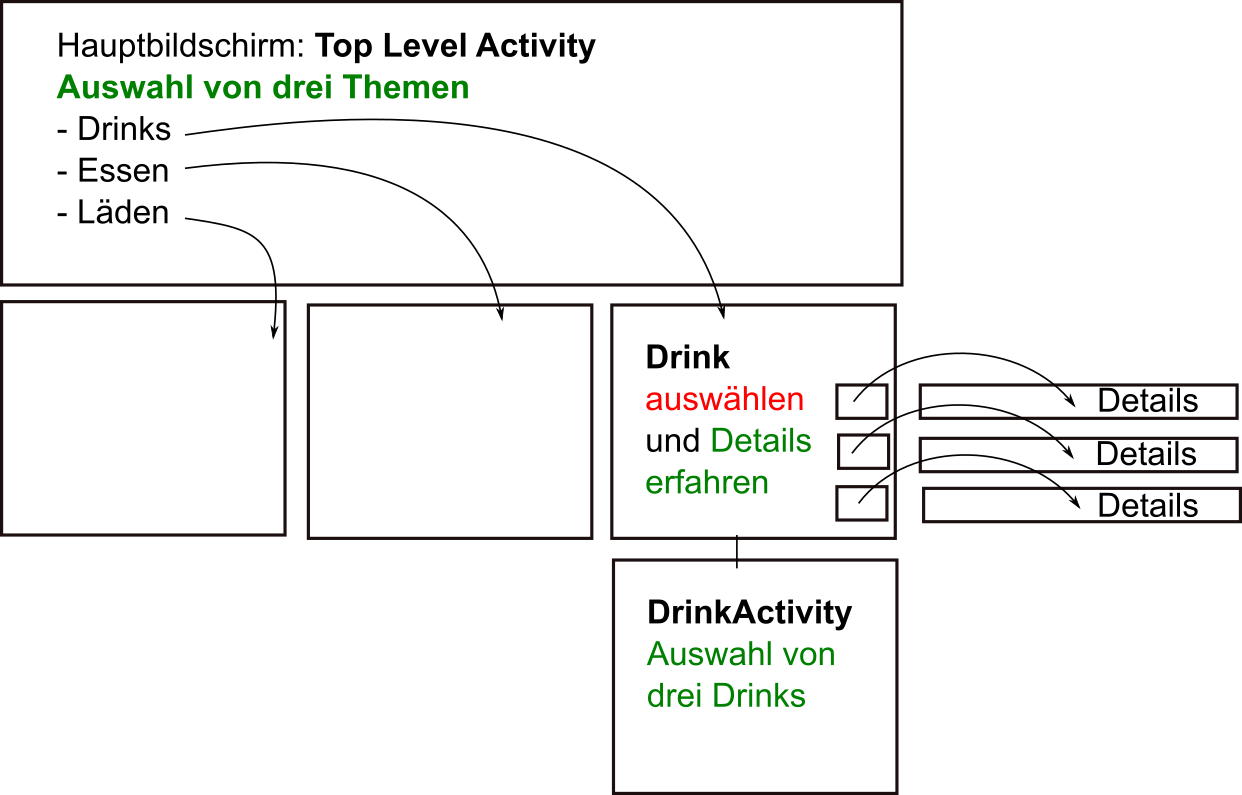
Auf dem Hauptbildschirm erscheint eine Liste von Optionen zur Auswahl, die man anklicken kann.
Nach der Auswahl wird die neue Aktivität aufgerufen.
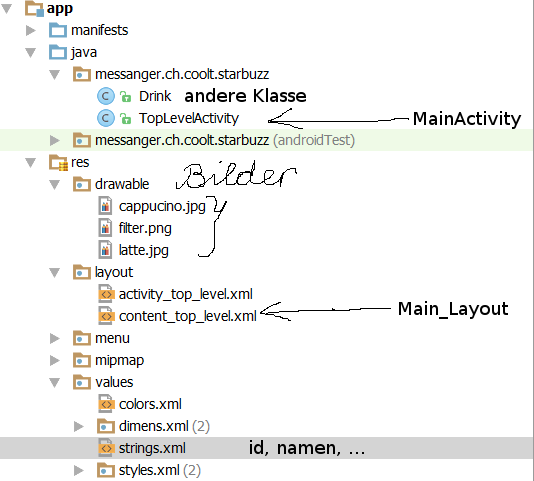
Java-Struktur
- Alle Aktivitäten (Auswahlen) erhalten eine Klasse.
Es gibt die Hauptklasse (hier Top Level Activity) und zu jeder Auswahl folgt eine Klasse (Klasse Drinks, Klasse Menüs, Klasse Standorte). - In der Anzeigeklassen wird das Anzeigen der Elemente verwaltet
- Soll nach der ersten Auswahl noch weitere Details angezeigt werden, erhalten diese auch wieder eine Aktivitätsklasse.
Anzeigeklasse
public class Drink {
private String name;
private String description;
private int imageResourceId;
// drinks is an array of Drinks
public static final Drink[] drinks = { // Bild hinzufügen
new Drink("Latte", "With milk", R.drawable.latte),
new Drink("Cappu", "With chocolate", R.drawable.cappucino),
new Drink("Filter", "With water", R.drawable.filter)
};
//Each Drink has a name, description, and an image ressource
private Drink (String name, String description, int imageResourceId){
this.name = name;
this.description = description;
this.imageResourceId = imageResourceId;
}
public String getDescription() {
return description;
}
public String getName(){
return name;
}
public int getImageResourceId(){
return imageResourceId;
}
public String toString(){
return this.name;
}
}
Layout Liste einbauen
Man findet unter Container die Listview. 
// top_level_activity.xml
<ListView
android:id="@+id/list_options"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:entries="@array/options" /> // die Auswahlnamen in Array
// string.xml
<resources>
...
<string-array name="options">
<item>Drinks</item>
<item>Food</item>
<item>Stores</item>
</string-array>
</resources>
Elemente der Auswahlklasse sollen antworten
Dies geschieht über einen EventListener. So hören die Klassenvariablen auf eine Aktivität. Um einen EventListener zu implementieren, muss die Methode OnItemClickListener() implementiert werden.
..
…