If the project should be under versioncontroll, don’t import it to the workspace.
Start it allways from the git-folder.
If the project should be under versioncontroll, don’t import it to the workspace.
Start it allways from the git-folder.
Siehe Chapter 6 aus: Head-First-Android-Development-2015
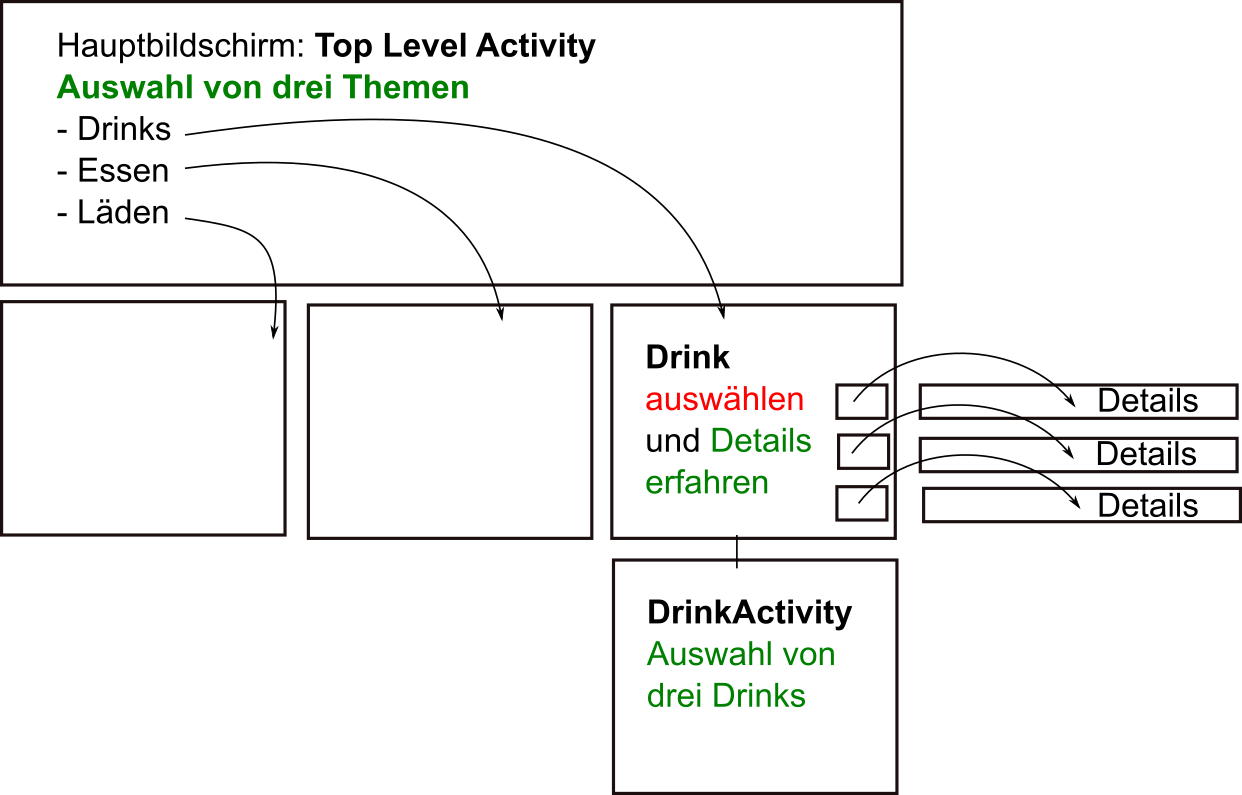
Auf dem Hauptbildschirm erscheint eine Liste von Optionen zur Auswahl, die man anklicken kann.
Nach der Auswahl wird die neue Aktivität aufgerufen.
Java-Struktur
Anzeigeklasse
public class Drink {
private String name;
private String description;
private int imageResourceId;
// drinks is an array of Drinks
public static final Drink[] drinks = { // Bild hinzufügen
new Drink("Latte", "With milk", R.drawable.latte),
new Drink("Cappu", "With chocolate", R.drawable.cappucino),
new Drink("Filter", "With water", R.drawable.filter)
};
//Each Drink has a name, description, and an image ressource
private Drink (String name, String description, int imageResourceId){
this.name = name;
this.description = description;
this.imageResourceId = imageResourceId;
}
public String getDescription() {
return description;
}
public String getName(){
return name;
}
public int getImageResourceId(){
return imageResourceId;
}
public String toString(){
return this.name;
}
}
Layout Liste einbauen
Man findet unter Container die Listview. 
// top_level_activity.xml
<ListView
android:id="@+id/list_options"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:entries="@array/options" /> // die Auswahlnamen in Array
// string.xml
<resources>
...
<string-array name="options">
<item>Drinks</item>
<item>Food</item>
<item>Stores</item>
</string-array>
</resources>
Elemente der Auswahlklasse sollen antworten
Dies geschieht über einen EventListener. So hören die Klassenvariablen auf eine Aktivität. Um einen EventListener zu implementieren, muss die Methode OnItemClickListener() implementiert werden.
..
…
Der Ordner res beinhaltet die visuellen Dateien (geschrieben in xml) und verwaltet deren Anbindung an die Java-Aktivitäten.
Die Variable R
An sie sind alle xml-Definitionen angebunden. Über sie kann in Java auf die einzelen Definitionen zugegriffen werden. Als erstes wird über diese Variable die generellen Layout-Settings in der Funktion getCreat() geladen.
setContentView(R.layout.activity_top_level);
In den folgenden Aktivitäten-Codes werden spezifische Settings zu einer Ansicht (Layout) über die Variable gesetz. Oft über die id-Referenz:
Toolbar toolbar = (Toolbar) findViewById(R.id.toolbar);
Hier werden die korrespondierenden Bilder über die Variable R geladen:
new Drink("Latte", "With milk", R.drawable.latte),
Der Ordner values
Die Einstellungen, die über die Variable R aufgerufen werden im Ordner ../res/values abgelegt. Alle Werte, die im Layout in der Datei ../res/layout/activiy_main.xml einer Ansicht zugewiesen werden, werden von Android Studio auch im Ordner ../res/ values/ abgelegt. Dort hat jede Variable einen Namen und einen Wert.
Beispiel
Variable fürs Zuweisen von Text
// activity_main.xml
<TexView
android text="string/Willkommen !" // Variablen-Wert setzen
/>
Speichern von Text per value
// activity_main.xml
<TexView
android text="@string/willkommen" // Variablen-Name setzen
/>
// string.xml
<recources>
<string name = "willkommen">Willkommen !</string> // name, Wert
</recources>
Speichern per reference ist vor allem beim Speichern mehrerer Auswahlen wichtig.
// activity_main.xml
<ListView
android:entries="@array/options"
/>
// string.xml
<string-array name="options"> // mehrere Namen für eine Liste
<item>Drinks</item>
<item>Food</item>
<item>Stores</item>
</string-array>
Android Studio zeigt die Dateien aus dem Unterordner App an. (Pfad dahin siehe unten in dieser Notiz zum Ablegeort der Android App Dateien im Datei Explorer).
In Java werden die Aktivitäten definiert.
In dem Ordner res (Ressourcen) das Layout.
Ausgeklappt sieht dies so aus:
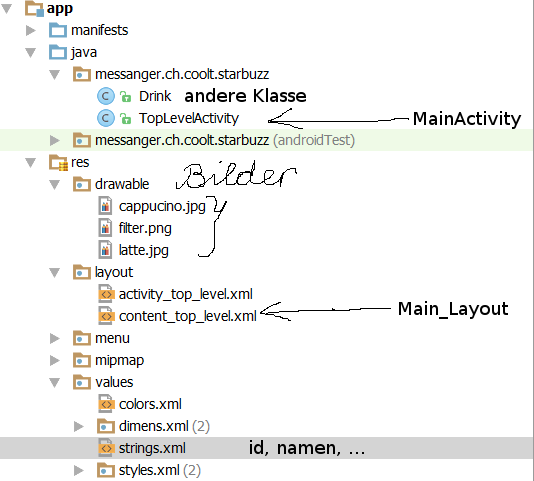
Im Datei Explorer
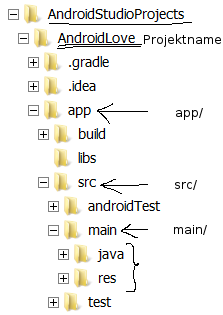
..
Prinzip von ViewGroups und Views
Auch das Layout ist hierarchisch bzw. über Vererbung aufgebaut. ViewGroups definieren die Grundansicht des Layouts wie z. B. ein <LinearLayout> oder ein <RelativeLayout> . Views werden als User Interface Components bezeichnet. Es handelt sich um die konkreten Teile auf dem Layout wie z.B. ein Text <TextView> , eine Taste, ein Schalter <Button> oder eine Eingabezeile <editText> .
Auswahl über visuelle Hilfe
Im Layout-Ordner kann man die Elemente per xml (siehe Tab Text) oder über Auswahl/Platzieren (im Tab Design) direkt auf ein simuliertes Gerät laden.

Widgets sind interaktive Eingaben, die eine Handlung auslösen.

TextFields sind aussschliesslich für Texteingaben gedacht. Android bietet bereits viele vordefinierte Input-Strukturen an, so dies eine Telefonnummer, ein normaler Text oder sei dies ein Pin.
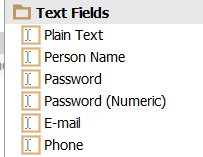
..
..
Aufbau Haupt- und Nebenhandlungen
Zwei Aktivitäten werden über eine Intent-Verknüpfung miteinander verbunden. Welche Aktionsklasse als nächstes aufgerufen werden soll, definiert man bei der Intent-Implementation. Diese geschieht bei der Funktionsdefinition der XXOnClickXX()-Funktion.
// Die Main Activity
public class ChooseFlower extends Activity(..){
protected void onCreate(){ // per default da
// details see below
...
}
// wird aufgerufen, wenn Taste gedrückt wurde
public void onClickFindFlower(View view){ // selber aufgebaute Funktion
...
}
}
public class TopLevelActivity extends AppCompatActivity {
protected void onCreate(Bundle savedInstanceState) {
// details below
// definiert Listener mit onItemClick() Methode
};
// Add listener to list view
ListView listView = (ListView) findViewById(R.id.list_options);
listView.setOnClickListener(itemClickListener);
}
Funktin onCreate()
protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_top_level); // Listener (needed after as argument) // in which the desired action is implemented for the click AdapterView.OnItemClickListener itemClickListener = new AdapterView.OnItemClickListener(){ // define own function: what happens after click public void onItemClick(AdapterView<?> listView, View v, int position, long id){ // handel position of list elements if(position == 0){ // first element in List Intent intent = new Intent(TopLevelActivity.this, DrinkCategoryActivity.class); startActivity(intent); } } };
Intent der etwas sendet
Bsp. Bein Klicken wird ein Email versendet
public void onSendMessage(view View){
...
Intent intent = new Intent(Intent.ACTION_SEND);
intent.putExtra(Intent.EXTRA_TEXT, messageTExt); // Text übergeben
starActivity(intent);
}
..
Methode set: Setter
Inhalt: Wechselt den Zustand der Variable
Struktur: void <name>(<argument>);
Bsp: stream.set( string );
Methode get: Getter
Inhalt: Liest einen Wert aus
Struktur: <type> <name>();
Bsp: command = getToken();
Ein Parser implementiert eine Code-Grammatik.
Für jede Regel wird eine Funktion erstellt.
class Token_stream {
public:
void set(string line);
Token get();
void put_back(Token t);
private:
istringstream calculation;
bool full = false;
Token buffer;
};
Eine Klasse beinhaltet Klassenvariablen und Klassen-Funktionen.
Instanzierung
Token_stream current_token_stream;
current_token_stream ist eine Instanz dieser Klasse. Alle Funktionen (die gebraucht werden um die Instanz zu verarbeiten) brauchen zuerst den Instanznamen.
current_token_stream.set(calculation_line);
Klassen-Funktionen
Jede Funktion einer Klasse muss nach der Klassendefinition definiert werden. Die Funktion braucht vor ihrem Namen die Klasse, zu der sie gehört.
void Token_stream::put_back(Token t) {
// check if token is already in buffer
if (token_buffer_full) {
throw std::overflow_error("buffer contains already a Token");
}
// set token in buffer
token_buffer = t;
token_buffer_full = true;
}
Funktionen einer Klasse, müssen nicht forward deklariert werden. Sie sind durch die Definition der Klasse bereits bekannt.
Klassen-Variablen
Es gibt meist wenige Klassenvariblen. Denn diese sind „global“ innerhalb der Klasse. Alle Funktionen können auf diese Zugreifen.
class Token_stream {
...
private:
istringstream calculation;
bool full = false;
Token token_buffer;
};
Typisch ist, dass sie im private-Teil der Klasse stehen.
Lokale Variablen
In jeder Klassen-Funktion werden zur Verarbeitung auch lokale Variablen gebraucht.
Token Token_stream::get() {
char c;
Token t;
calculation >> c;
if (isdigit(c)) {
t.kind = 'n';
t.value = c;
} else if (c == '\0') {
t.kind = 'q';
}
return t;
}