Liste zu String
list = [ „ha“, „ba“, „la“ ]
string = „“.join(list) out: „habala “
string = “ „.join(list) out: “ ha ba la „
Monat: September 2015
2-dimensionales Array
Ziel
3 x 3 Array mit 0 initialisieren
Struktur: List of list
Liste mit 3 Elementen, die selbst Listen sind
array = [ [0, 0, 0], [0, 0, 0], [0, 0, 0] ]
Umsetzung simple
element = [ „0“] * 3
array = element * 3
Umsetzung variabel
for i in range(3):
. array.append( [„0“ * 3 ]
RAM
SRAM (Statisches RAM)
Speicherzellen sind mit Transistoren realsiert. Sie behalten den Zustand auch im Ruhezustand. Bei steigender Flanke werden die Bits übertragen.
DRAM (Dynamisches RAM)
Speicherzellen sind Kondensatoren. Diese verlierten die Daten und muss zyklisch „refreshed“ werden. Dies erfolgt Zeilenweise. Jede Zeile wird in einen Zeilenbuffer geladen, dort verstärkt und zurückgeladen.
Das Auffrischen muss auch im Ruhezstand statt finden, weshalb energiesensitive Geräte auf DRAM verzichten
DDR-SRAM (Double-Data-Rate SRAM)
Die Verdopplung der Datenübertragung erfolgt, weil auch bei der fallenden Flanke Bits übertragen werden. Ausgelesen werden 2 Bit aufs Mal, wobei eines direkt mit dem Takt verarbeitet werden kann und das zweite in den Speicher abgelegt wird und zusätzlich ausgelesen werden muss.
Es braucht daszu die doppelte Busbreite, als für SRAM

PC Bewertung
Prozessor
LenovoThinkPad Ines: Core-i7, CPU, 620@2.0 GHz x 4
Core i7-620M, 2 x 2.6 GHz
Latop M30 Ines: Core-i5-4210U, 4 x 1.7 GHz
OS-Typ
LenovoThinkPad Ines: 64 Bit
Latop Ines: 64 Bit
Memory
LenovoThinkPad Ines: 4 GB DDR3-SRAM, @ 1 GHz
Latop Ines: 4 GB
Disk aktuell: keine SSD-Harddisk
Lenovo ThinkPad Ines: 320 GB , 5400RPM
Latop M-30 Ines: 500 GB, 5400 rpm, HDD
Graphics
LenovoThinkPad Ines: Intel: Ironlake Mobile
Latop Ines: HD Graphics 4400, @1GHz
Anschlüsse
LenovoThinkPad Ines: 3 x USB 2.0, RJ45, VGA, Audio 2 x 3.5mm Klinke
Latop Ines: 3 x USB 3.0, RJ45, HDMI, Audio 1 x 3.5 Kllinke
www.notebookcheck.net
Zeilenumbruch nur für Code
return = str( var_1) + “ banana“ + str( var_2 ) \
. “ apricots“
return = var_1 * 2 + 0.1 * var_2 \
+ result_a – result_b
\ auf nächsten Zeile weiterzucoden,
. wie wenn alles in einer Zeile stünde
for
list
list = ["a", "b" ]
for i in list: # i sind Elemente
print i # output: a
# b
range(2) = [ 0, 1 ] # ist nummerierte Liste
for i in range(2):
print i # output 0
# 1
for i in range( len(list) ):
print list[i] # output: a
# b
………………………………………………………………………….
dictionary
dict = {„a“=5,
. „b“ = 8 }
for i in dict: // i sind keywords
. print i // output a
. // b
print dict(„i“) // output 5
. // 8
Datentyp
list_1 = [ 2, 7, 9]
type( list_1 ) -> < type ‚list‘>
type( list_1[0]) -> < type ‚int‘ >
list_2 = [„hoi“, „ciao“ ]
type( list_2[0]) -> < type ’str‘ >
dict = { „wurst“ : 5,
“ brot“ : 2 }
type( dict) -> <type ‚dict‘ >
type( dict[„wurst“]) -> < type ‚int‘ >
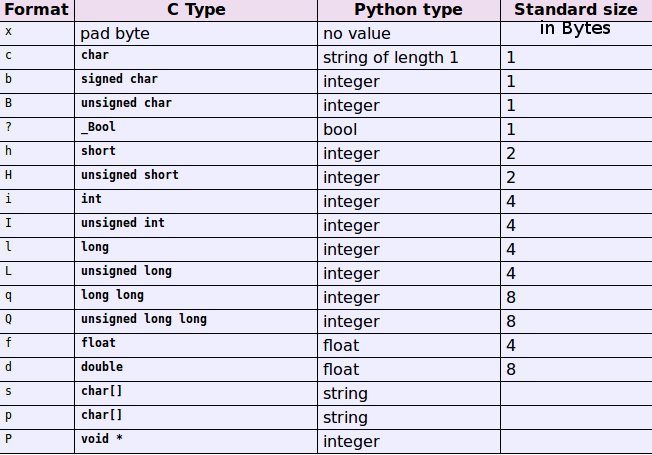
Bytes einlesen
Byte-Struktur
– Formatvariablen definieren definieren Datenstruktur
– Formatvariablen stehen in einem String
– für jede Formatvariable muss eine Variable mitgegeben werden
– folgen grosse Datenpakete als, muss deren Länge
. bekannt sein und wird vor der Stringvariable eingefügt
– “ > “ bedeutet big endian, “ < “ littel endian
command = pack(‚ >BH‘ + str(length) + ’s ‚, typ, command, length, data)
Vor Daten Schlüsselwörter einfügen
data = pack(‚ >BBH’+str(length)+’s ‚, testnumber, time, command, length, data)
Schlüsselwörter vor Data extrahieren
testnumber = unpack(‚>B‘, data[0:1])
time = unpack(‚>B‘, data[1:2])
Daten ohne Schlüsselwörter
data[:4] die ersten 4 Bytes werden weggelassen
Big Endian / Littel Endian
big endian = normal a = (‚>B‘, 3) output a = 00 03
little endian a = (‚<B‘, 3) output a = 03 00
Info
In Python werden Daten als String übergeben. Sollen diese eine bestimmte Byte-Struktur haben, helfen die Funktionen pack() and unpack().
import struct *